PercHead: Perceptual Head Model for Single-Image 3D Head Reconstruction & Editing
CVPR 2026 (Highlight)
Our Perceptual Losses
Released as standalone, drop-in PyTorch modules. Try them out!






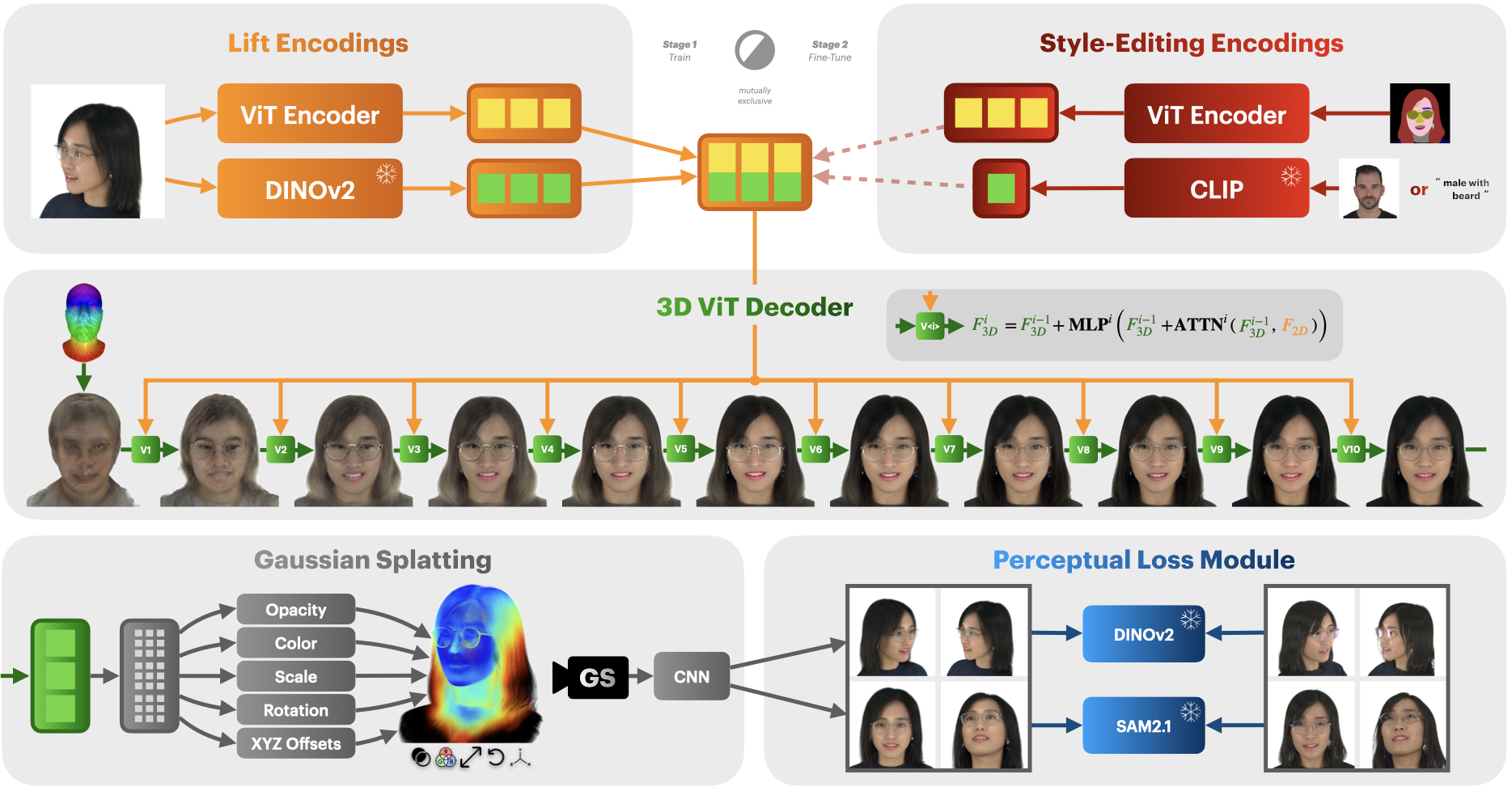
Overview of Our Method. Our framework supports 3D Reconstruction from a single image and 3D Editing from a segmentation map and style input. We only need to adapt the encoders of our ViT-based architecture between the two tasks. We train on multi-view datasets and extend them with single-view data to improve diversity, without degrading 3D consistency. At the heart of our method is the supervision through DINOv2 and SAM 2.1. Our perceptual loss compares deep image representations, which helps us avoid signals from pixel-level differences.









Processing in the video is sped up.

































@inproceedings{oroz2026perchead,
title={Perchead: Perceptual head model for single-image 3d head reconstruction \& editing},
author={Oroz, Antonio and Nie{\ss}ner, Matthias and Kirschstein, Tobias},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={4097--4108},
year={2026}
}